학습목표
(1) optimization basics (최적화 기초)
(2) can we capture the esence of word meaning more effectively by counting (카운트를 통해 더 효과적으로 중요한 의미의 단어를 포착할 수 있을까?)
(3) the GloVe model of word vectors
(4) Evaluating word vecotrs
(5) Word senses
(5) Review of classification and how nueral nets differ
(6) Introducing neural networks
(7) to be able to read word embeddings papers
--------------------------
word2vec parameters and computations
- 유일한 매개변수는 단어 벡터
- 단어에 대해 외부 단어 벡터와 중심 단어 벡터가 있음
- 확률을 얻기 위해 내적한다. 특정 외부 단어가 중앙 단어와 나타날 가능성에 대한 점수를 얻기 위해 내적을 취함
- 소프트맥스 변환을 사용하여 해당 점수를 확률로 변환
Bag of words
단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법이다. 중앙 단어 옆에 있는지 어디에 있는지 신경을 안 쓴다.
- 확률 추정치는 동일하다. (문맥이나 위치에 의존하지 않고 단순히 빈도에 기반하여 계산하기 때문에, 특정 단어가 어느 위치에 등장하든 그 단어의 출현 확률은 동일하다.)
- 중심단어의 맥락에서 적어도 자주 발생하는 경우, 합리적으로 높은 확률을 부여하고 싶음
- 0.01 같은 확률을 이야기할 가능성이 높음. 어떻게 할 수 있을까?
반대로 word2vec 모델이 이를 달성하려면 의미가 유사한 단어를 고차원 벡터 공간에 가까이 배치함.

좋은 단어 벡터를 어떻게 배울 수 있을까?
- 진전을 가능하게 하는 매개변수와 관련하여 손실함수의 기울기를 계산해야함
1) 무작위 단어 벡터로 시작
2) 각 차원에서 0으로 시작
각 좋은 단어 벡터를 배우기 위해서는 손실함수를 최소화 해야하고 경사 하강법(Grdient Descent)는 값을 바꿈으로써
손실함수 J(θ) 를 최소화할 수 있다.
아이디어: 현재 값 으로부터 J(θ)의 기울기를 계산하고, 음의 기울기 방향으로 작은 step를 진행한다.
반복한다.
step size: 너무나도 작으면 계산하는데 시간과 비용이 커지게 되지만 너무 크게 되면 최적값을 찾을 수 없게 된다.
(1) 파라미터 초기값을 선택하여 임의로 초기화한다.
(2) 기울기를 계산한다.
(3) 기울기 정보를 사용해 현재 파라미터를 수정한다. 이때 기울기가 가장 크게 증가하는 방향 (기울기가 가장 큰 음의 방향)으로 파라미터를 이동한다.
(4) 일정한 조건이 만족될 때까지 반복한다.
Gradient descent (경사 하강법)
- 학습률이나 단계 크기의 α를 사용하여 gradient의 negative direction으로 이동
- 매개변수 θ에 새로운 값 제공
경사 하강법의 업데이트 식 (Update Equation)
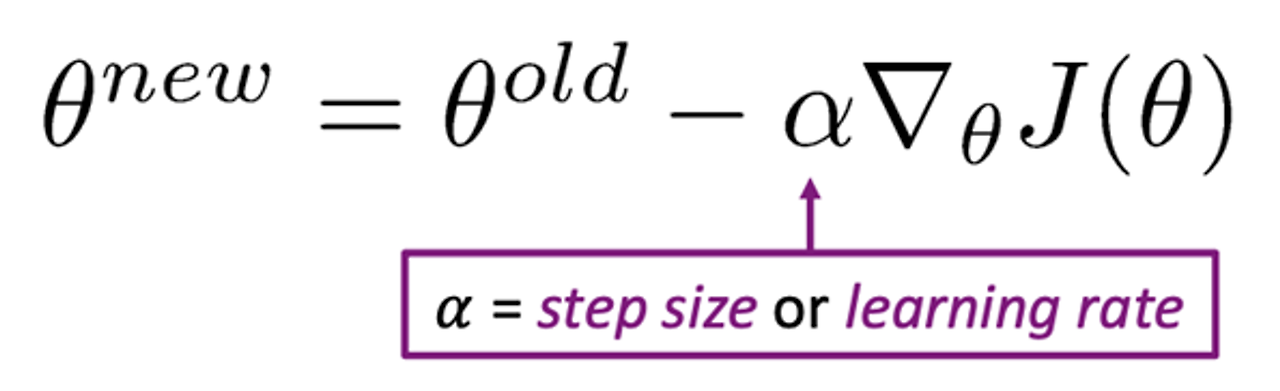
θ : 모델의 매개변수 벡터
α: 학습률 or step size
∇θJ(θ): 손실 함수 J(θ)에 대한 θ의 gradient
매개변수 θ 를 J(θ) 의 gradient에 따라 업데이트
학습률은 step size를 조절
new vector= old vecotr – 학습률 * 손실함수의 기울기
- 단일 매개변수에 대한 업데이트 식
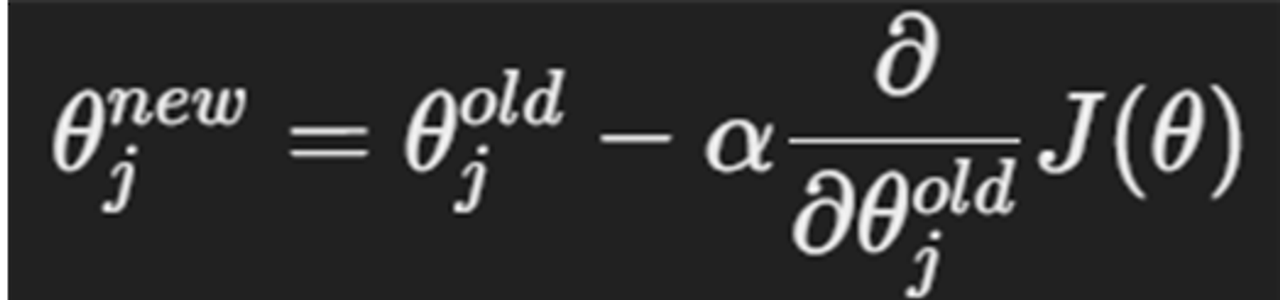
while True:
theta_grad = evaluate_gradient(J, corpus, theta)
#현재 매개변수 θ에서 손실함수 J의 기울기
theta = theta - alpha * theta_grad
#기울기와 학습률에 따라 θ를 업데이트- J(θ) 모든 중심 단어에 대한 합계를 계산
Gradient descent의 문제점
- 모든 단어에 대해 계산한다면 매우 비싸진다.
- 전체 단어 코퍼스에서 진행하기 때문에 시간도 오래 걸린다.
SGD (Stochastic gradient descent, 확률적 경사 하강법)
- 간단히 하나의 중심 단어 또는 작은 배치를 선택한다.
- 장점: 계산이 빠르다는 장점이 있다.
- 단점: 작은 부분만 보기 때문에 매우 잡음이 많고 불량하다.
Sparsity

많은 값이 0을 가지는 현상
- 대부분의 값이 0이므로, 이를 저장하기 위해 많은 공간을 낭비.
- 효율적으로 저장하려면 특수한 데이터 구조가 필요
- 희소 행렬과의 계산은 불필요한 0 값의 연산을 포함하게 되어 비효율적
- overfitting
- 0이 많아서 계산 비용이 낮음
- 기계 학습 모델을 단순화
Low-dimensional vectors
simple count Co-occurrence vectors의 문제를 해결하기 위해 저차원 벡터 사용
- dense vector: 중요한 정보를 고정된 작은 차원에 저장
- 차원수 25~1000 차원으로, Word2Vec와 비슷
그렇다면 차원수를 어떻게 줄일까?
SVD (Singular Value Decomposition, 특이값 분해 )
행렬 𝑋를 3개로 분해하는 방법
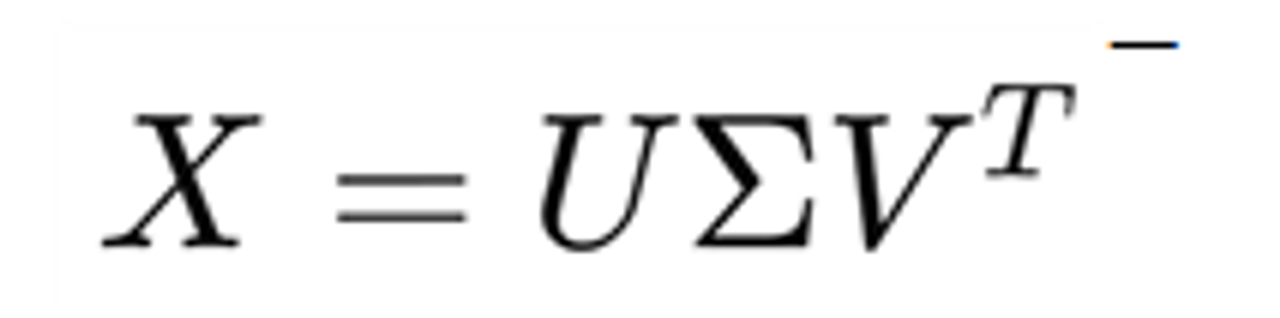

- 차원 축소: 행렬 𝑋를 축소
- k개의 특이값 유지: SVD를 통해 얻은 특이값 중 상위 𝑘개의 특이값과 그에 대응하는 벡터만을 유지.
=> 𝑋의 최적 랭크 𝑘근사(rank-k approximation)를 만든다
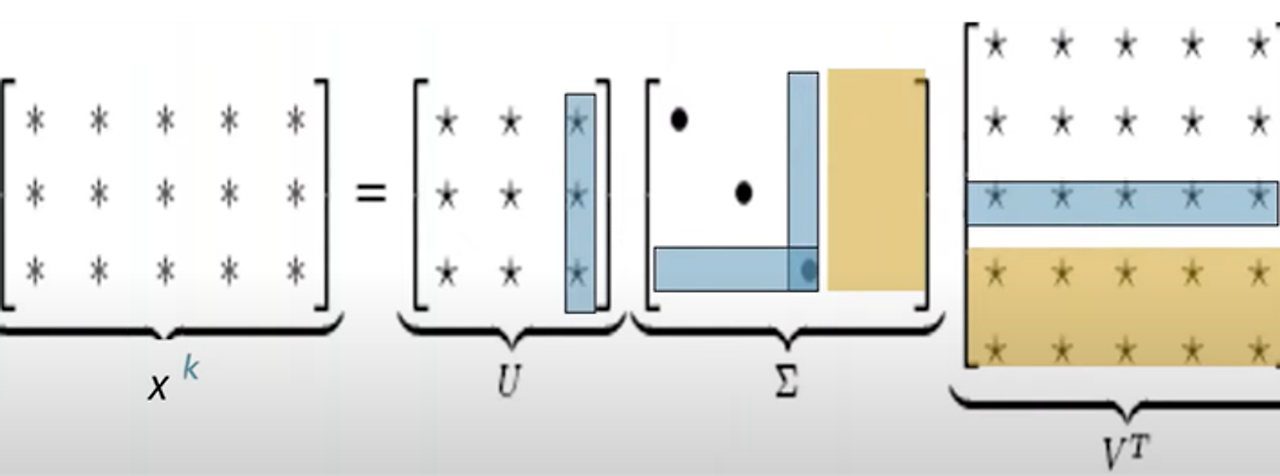
파란색 부분(사용되지 않는 부분)과 노란색 부분(값이 없는 부분과 하위 벡터)은 버리게 되어 차원을 줄일 수 있다.
SVD를 사용할 수 없는 이유
(1) Raw Counts
- raw counts로 SVD를 실행하면 성능이 나쁘다.
- raw counts는 빈도 단어와 저빈도 단어 사이의 큰 차이를 보이고, 이러한 차이는 noise를 많이 포함할 수 있다.
(2) function words
- "the", "he", "has" “after” 등등... 너무 자주 등장
- 중요한 단어보다 기능어의 빈도가 높아진다.
Hacks
(1) raw counts에 로그를 취하여 변환하여 고빈도 단어의 영향을 줄이기
- log(frequency)
(2) 최대값 제한
- 빈도의 최대값을 𝑡로 설정 𝑡≈100
(3) 가까운 단어에 높은 가중치 부여
(4) Pearson 상관 계수 사용
- 빈도 대신 Pearson 상관계수를 사용하여 단어 간의 관계를 계산하고, 음수 값을 0으로 설정
(5) function words 무시하기
COALS(Correlation-based Analogy and Latent Structure)
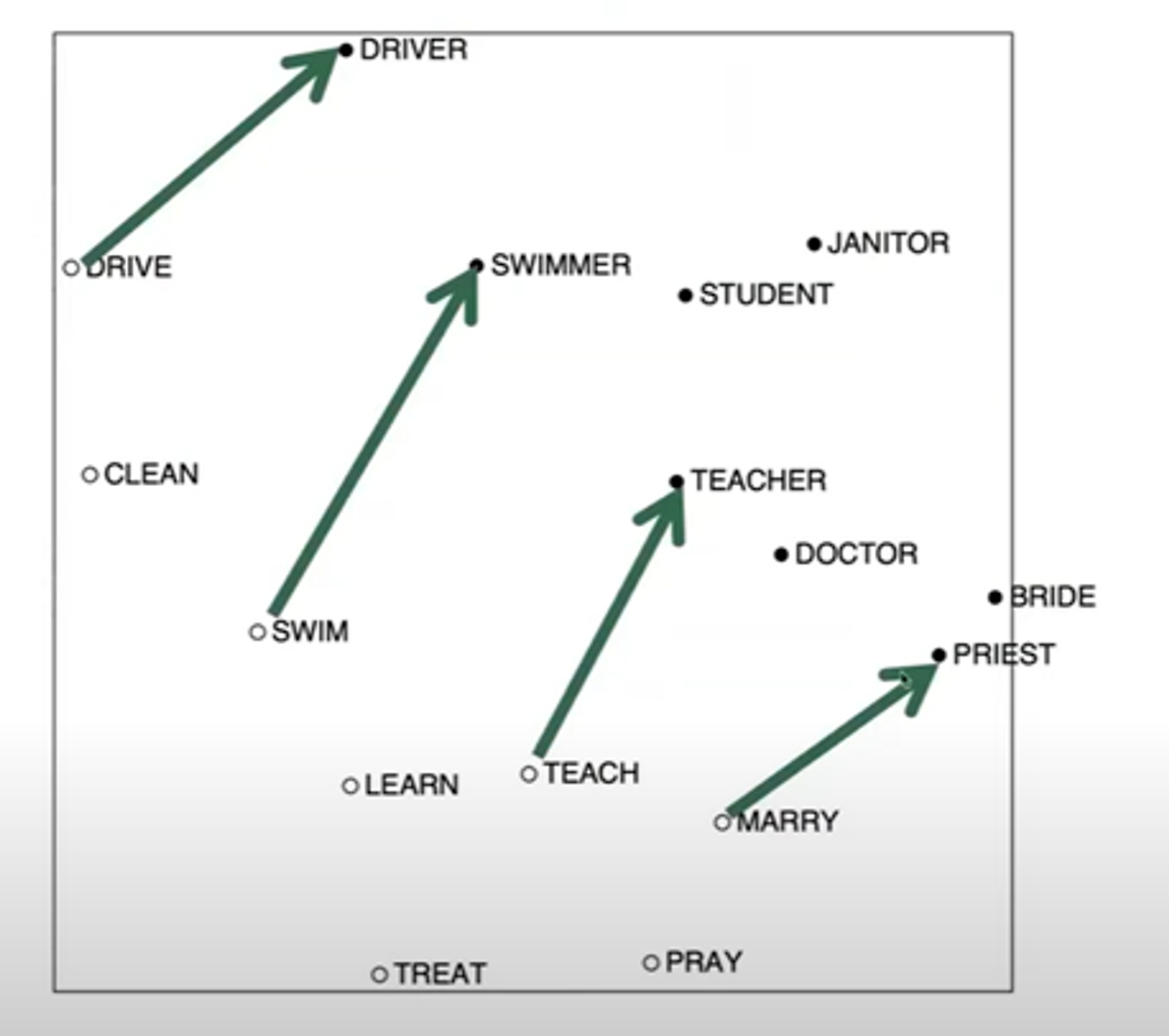
단어 공동 출현 정보(word co-occurrence information)를 사용하여 단어 간의 의미적 유사성을 계산
- 공동 출현 빈도와 상관관계를 기반으로 단어 벡터를 생성
- 이러한 시각화를 통해 단어 간의 의미적 패턴이나 규칙성을 발견할 수 있다.
|
|
Count-base
|
Direct prediction
|
|
대표 모델
|
- LSA (Latent Semantic Analysis) - HAL(Hyperspace Analogue to Language) - COALS (Correlation-based Analogy and Latent Structure)
|
Skip-gram/CBOW (Continuous Bag of Words): Word2Vec model) NNLM (Neural Network Language Model) HLBL (Hierarchical Log-Bilinear Model) RNN (Recurrent Neural Network)
|
|
특징
|
Fast training Efficient usage of statistics: Primarily used to capture word similarity Disproportionate importance given to large counts 훈련 속도가 빠르고 통계적 정보를 효율적으로 사용하지만, 주로 단어 유사성만을 포착하고 큰 빈도수에 과도한 중요성을 부여하는 단점
|
Generate improved performance on other tasks Can capture complex patterns beyond word similarity Scales with corpus size Inefficient usage of statistics 대규모 데이터셋에서도 잘 동작하고 다른 작업에서도 성능을 향상시키며, 더 복잡한 패턴을 포착할 수 있지만, 통계적 정보를 비효율적으로 사용
|
GloVe
word co-occurrence information 의 비율을 사용하여 의미 요소를 벡터 차이로 인코딩
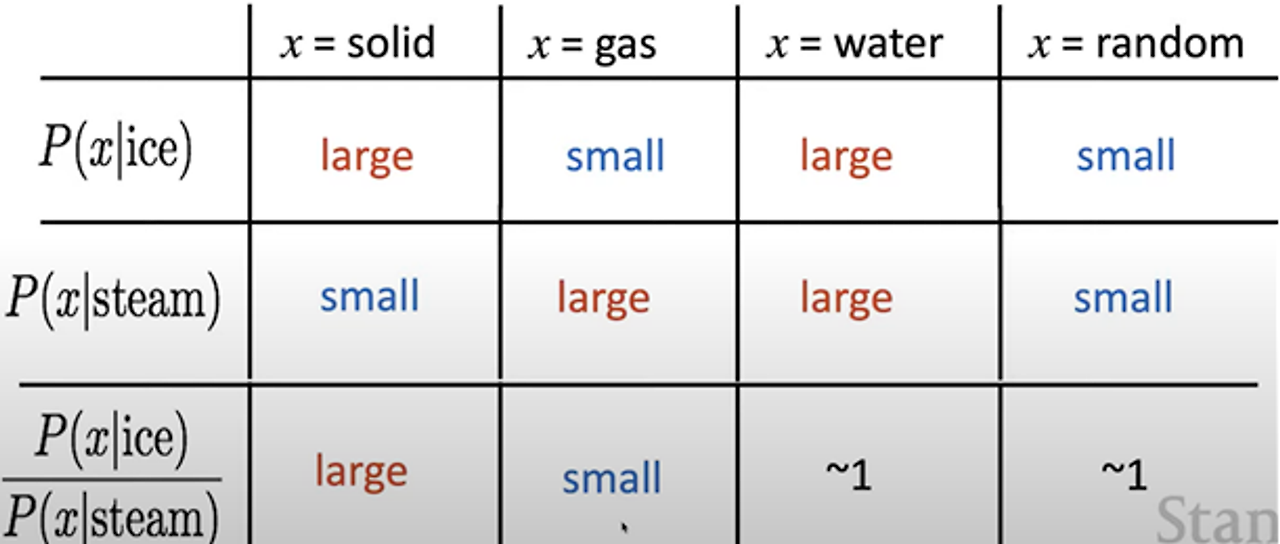
- ex) 단어 x가 주어진 단어 ice 또는 steam과 함께 나타날 확률을 고려
- 이러한 확률의 비율이 특정 의미 요소( 고체, 기체, 물 등)를 인코딩
word co-occurrence information 의 비율을 통해 특정 의미 요소를 인코딩할 수 있다.
=> GloVe 모델에서 단어의 의미적 유사성을 표현하는 데 사용
Q. 어떻게 하면 벡터 공간에서 동시 발생한 확률의 비율을 선형적으로 포착할 수 있을까?
A. Log-bilinear model with vector differences (로그-이중선형 모델의 벡터 차이)
Log-bilinear model
wi⋅wj=logP(i∣j)
벡터와 확률 간의 관계
내적 값이 클수록 두 단어는 문맥에서 자주 함께 등장함
변수
- wi : 단어 i의 벡터.
- wj : 단어 j의 벡터.
- wi⋅wj: 단어 i 와 j 의 벡터 내적(dot product).
- P(i∣j) : 단어 j가 주어졌을 때 단어 i 가 등장할 조건부 확률.
단어 벡터 간의 내적이 단어 공동 출현 확률의 로그 값과 일치한다. 특히, 두 단어 벡터 간의 차이를 사용하여 공동 출현 확률의 비율을 포착할 수 있다.
wx⋅(wa−wb)=log(P(x∣a)P(x∣b))
- 단어 벡터 간의 내적이 단어 공동 출현 확률의 로그 값과 일치한다.
- 특히, 두 단어 벡터 간의 차이를 사용하여 공동 출현 확률의 비율을 포착할 수 있다.
x가 a에서 더 자주 등장할 확률이 높다면
wx⋅(wa−wb) 값은 양수
x가 b에서 더 자주 등장할 확률이 높다면,
wx⋅(wa−wb) 값은 ㅇ,ㅁ수
GloVe 모델 Loss function
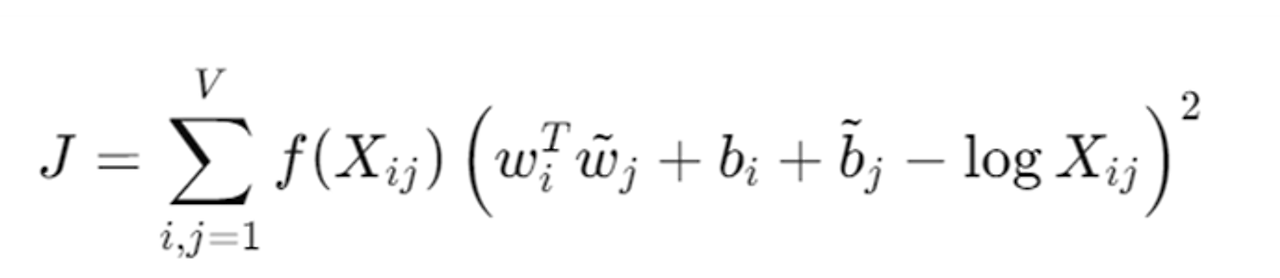

가중치 함수 𝑓
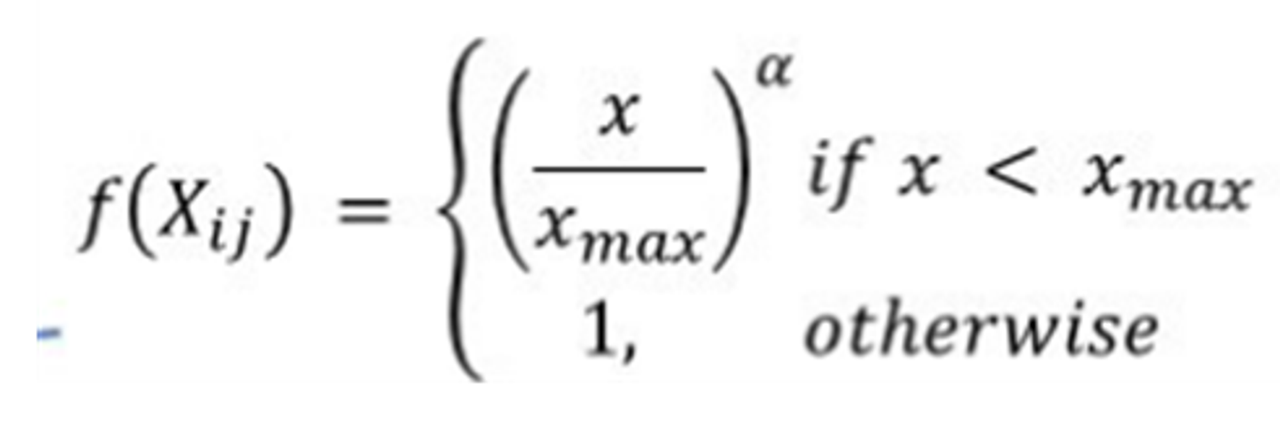
- 빈도가 너무 높은 경우: 매우 자주 나타나는 단어 쌍 은( "the"와 "is")은 구문적 특성(syntactic properties)
- 그대로 사용하면 모델이 구문적 특성을 overfitting할 수 있음.
- 빈도가 너무 낮은 경우: 매우 드물게 나타나는 단어 쌍은 잡음(noise)일 가능성이 큰데, 이를 overfitting 하는 것을 막아야함
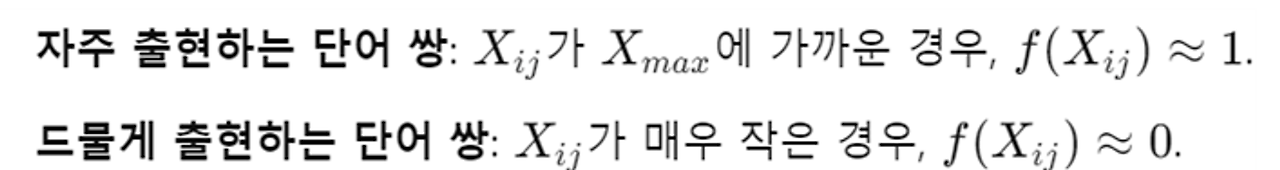
GloVe 모델의 장점
- Fast training
- Scalable to huge corpora: 대규모 코퍼스에서도 확장 가능
- Good performance even with small corpus and small vectors: 작은 코퍼스와 작은 벡터로도 좋은 성능
GloVe 모델의 결과

처음 들어보는 개구리 종류도 분류를 잘함
Word embedding Evaluation
단어 임베딩 모델들을 평가하기
- 내적평가
- 외적 평가
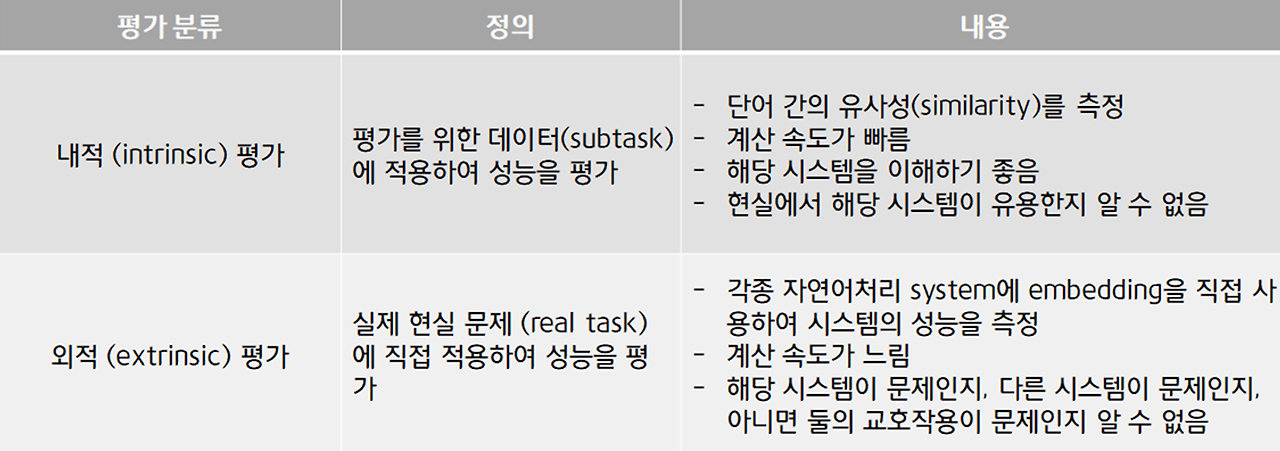
intrinsic word evaluation example
- 작은 task에 대해 모델을 평가
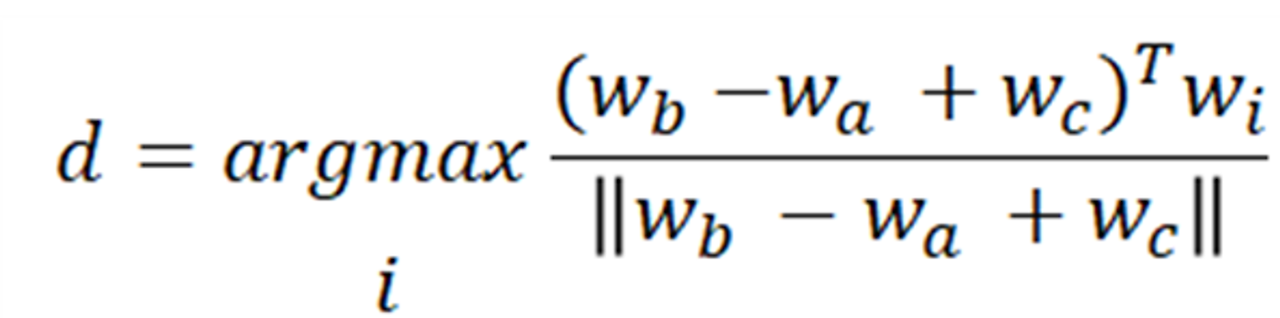
man -> woman일 때, king -> _______ _______에는 queen이 나와야하는데 진짜 나오는건지 확인한다.
a:b :: c:?
?에 들어갈 단어를 유추
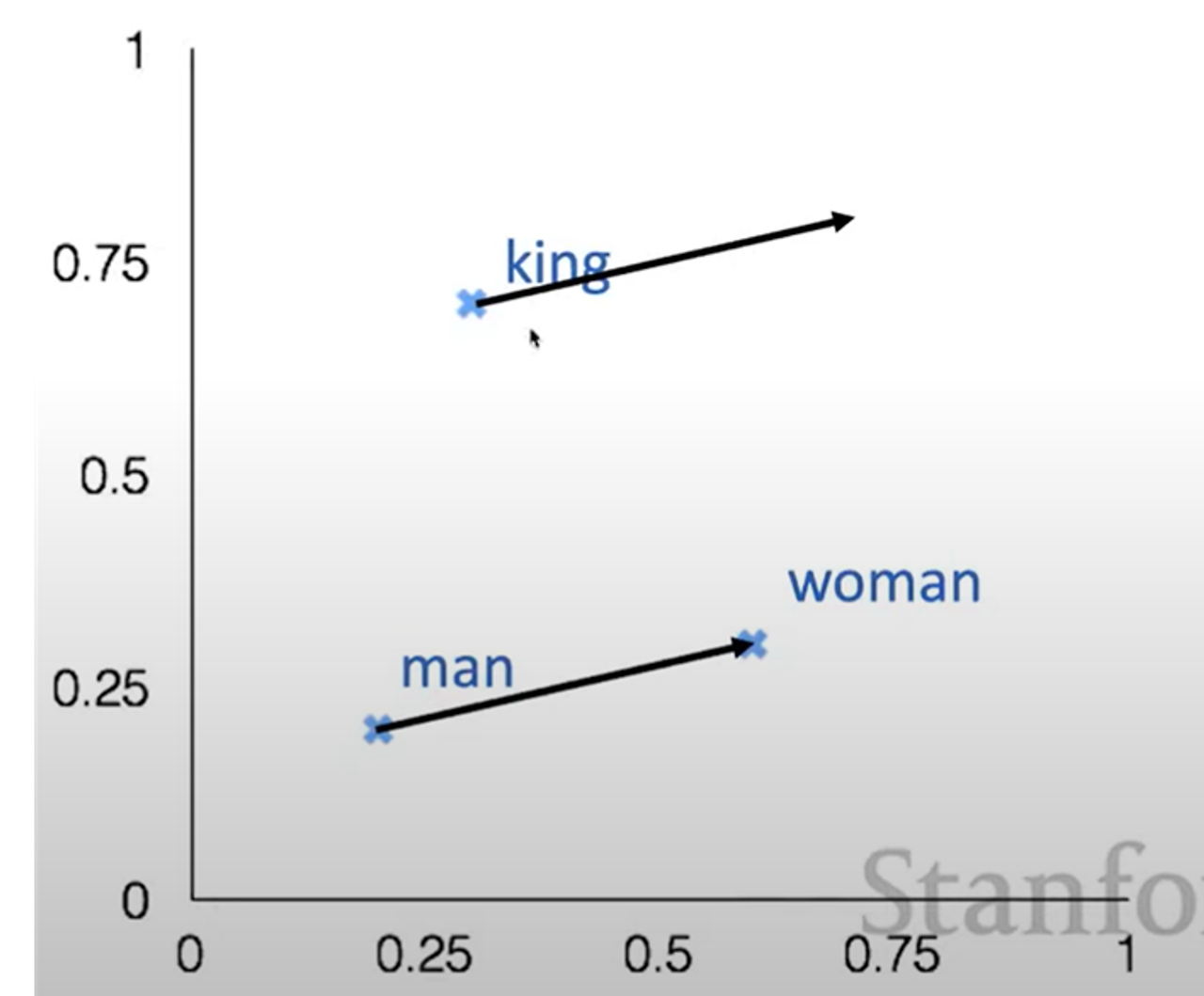
Glove Visualizations
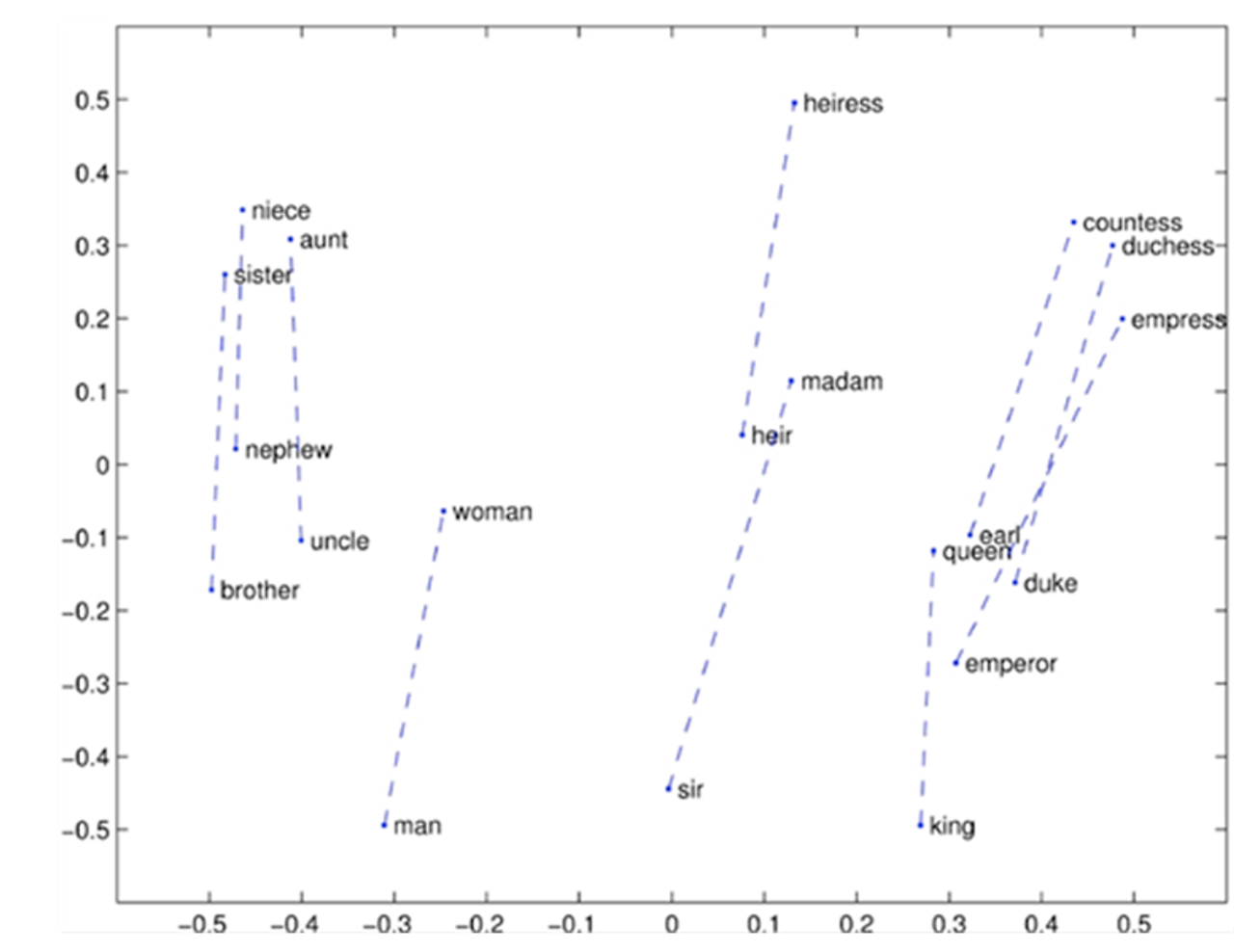
opposite
반의어 관계에 있는 여러 단어 쌍들이
비슷한 간격으로 2차원의 공간 내에 위치
- COALS와 마찬가지로 강력한 선형 구성 요소를 가짐
(COALS가 무엇인지..??)
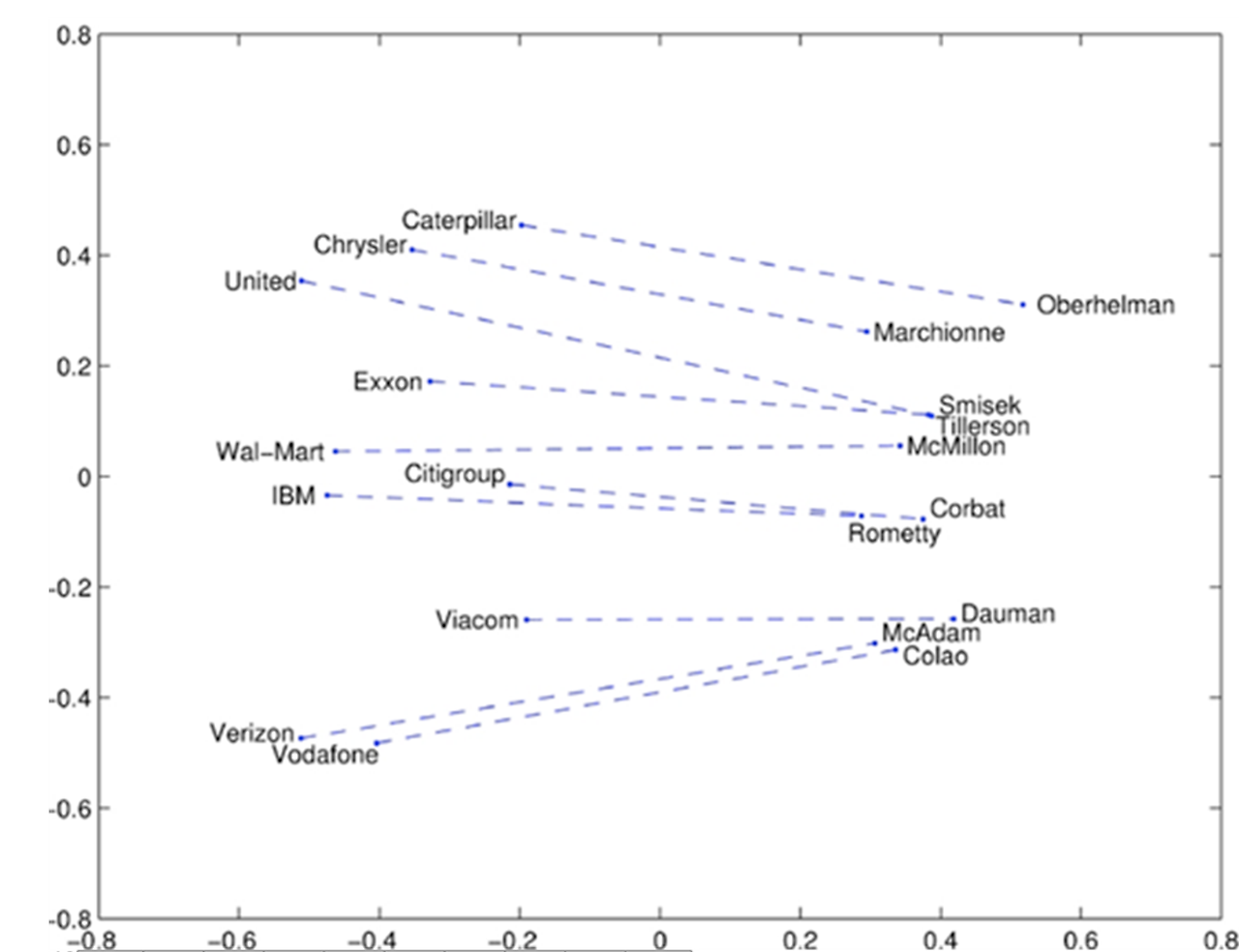
company 집단에 속하는 단어는 좌측 CEO 집단에 속하는 단어는 우측에 몰려있음
company와 CEO의 거리는 각 쌍마다 비슷
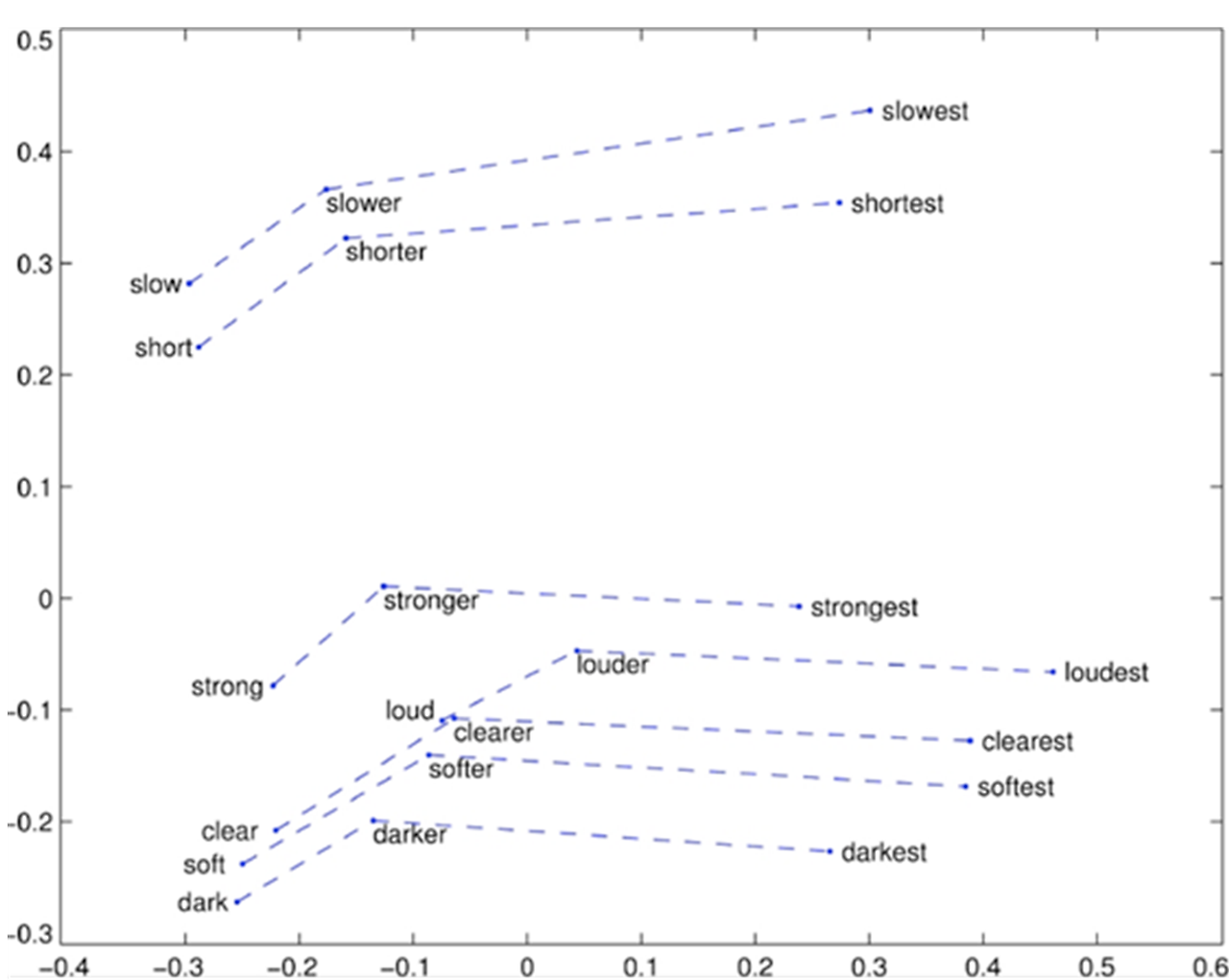
superlatives 단어의 원형 - 비교급 - 최상급을 2차원 공간에 표현한 후
선을 그었을 때의 형태가 유사 slow- slower – slowest
Analogy evaluation and hyperparameters
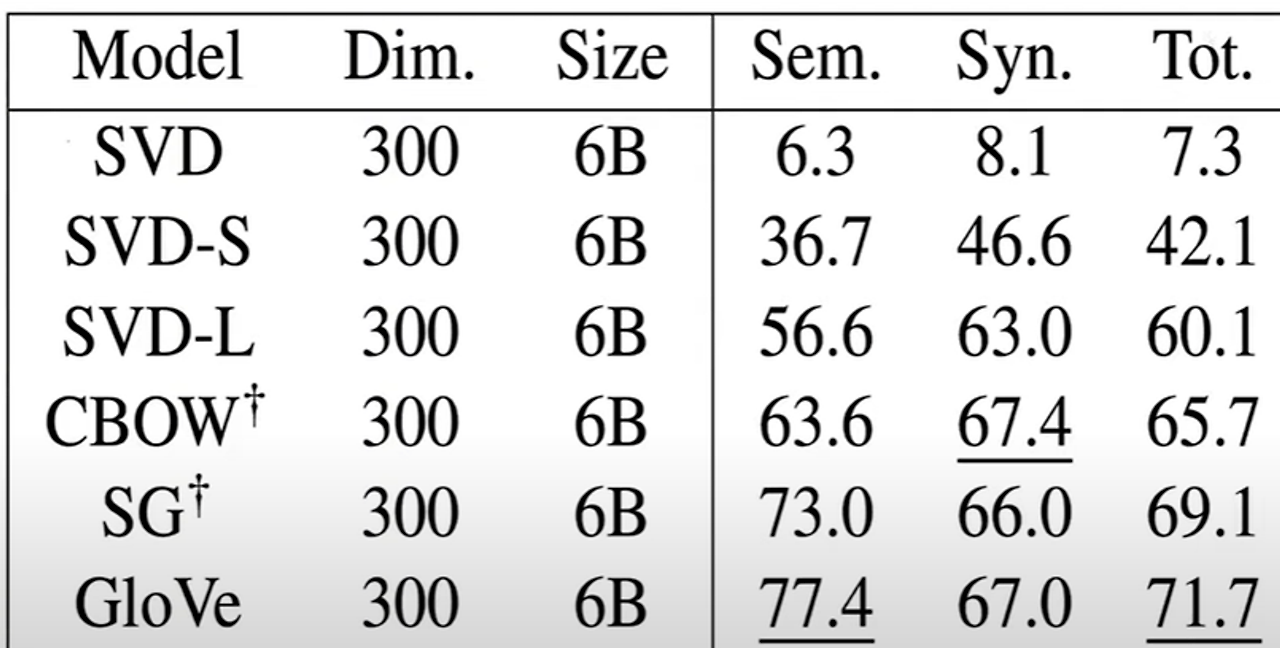
semantic & syntatic을 기준으로 평가
- SVD: unscaled Co-occurrence counts를 사용하여 SVD를 하면 값이 매우 나쁘다 (7.3)
- SVD-S & SVD-L은 COALS 모델과 비슷(60.1)
- WORD2VEC MODEL -CBOW -SG -GloVe 이게(71.7) 훨씬 좋음~
하지만 실제로는 아래 데이터들이 더 좋은 데이터를 사용했기 때문에 좋은 결과가 나오는 것 (위키피디아)
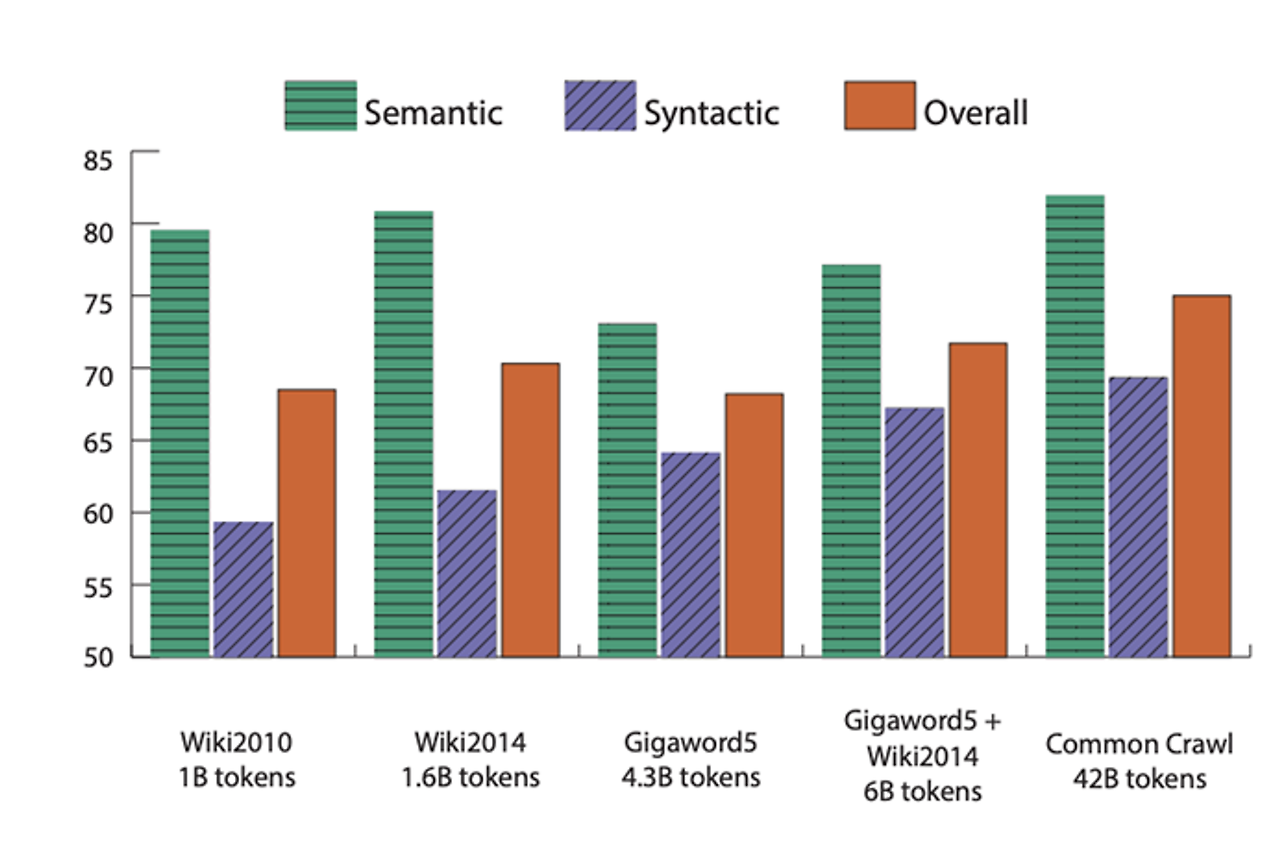
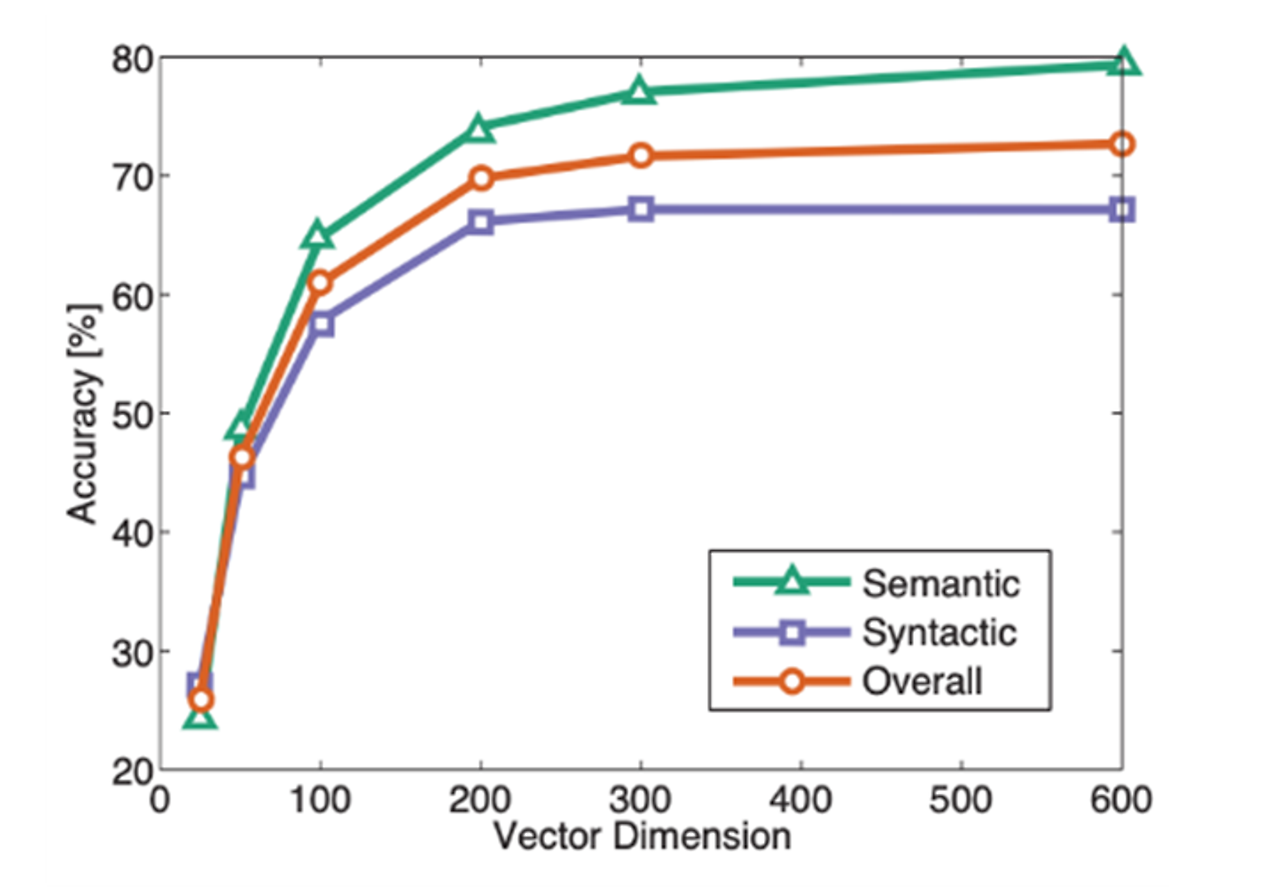
-
Another intrinsic word evaluation
Human evaluation
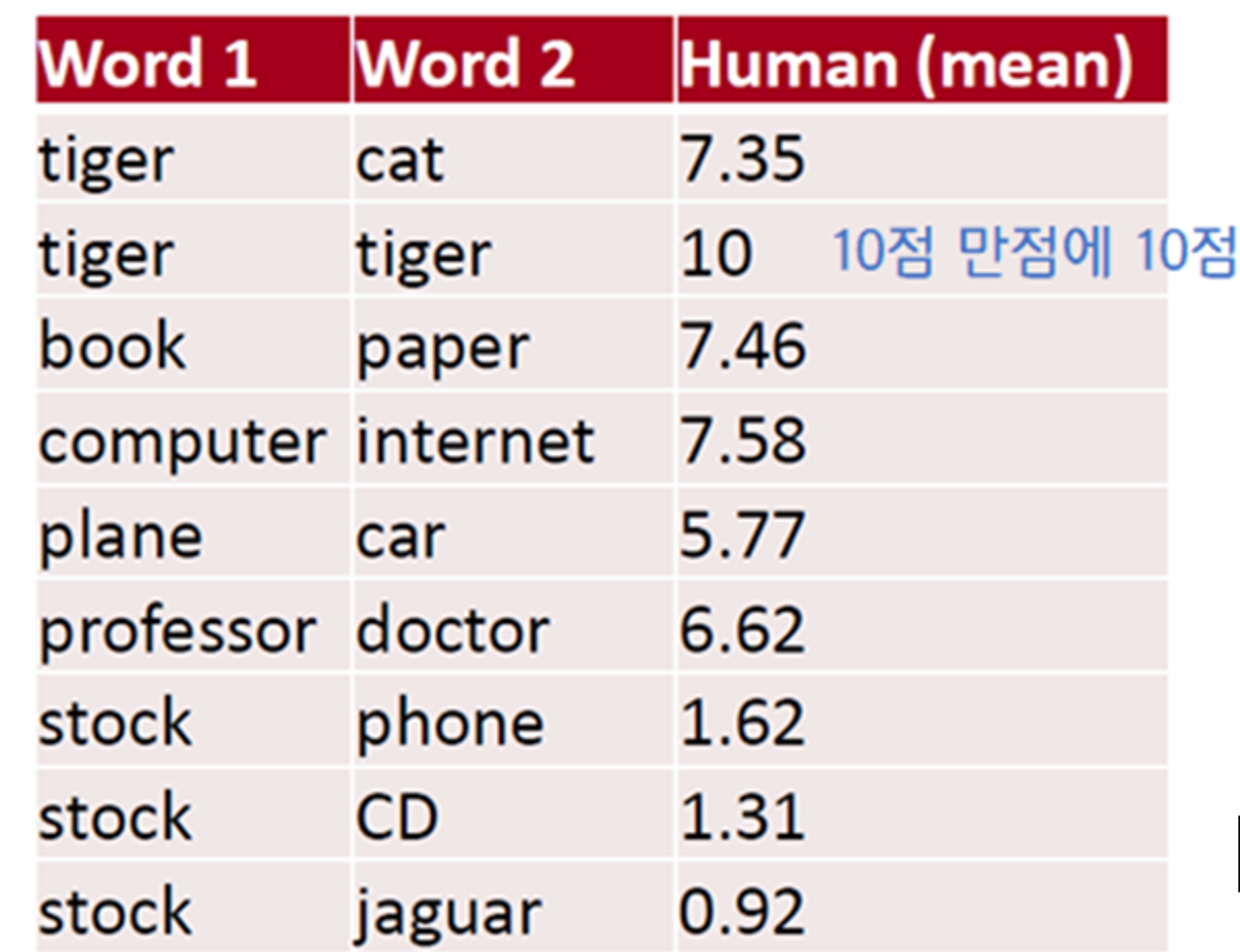
- 일련의 단어 쌍을 미리 구성한 후, 사람이 평가한 점수와 단어 벡터 간 코사인 유사도 사이의 상관관계를 계산해 단어 임베딩의 품질을 평가
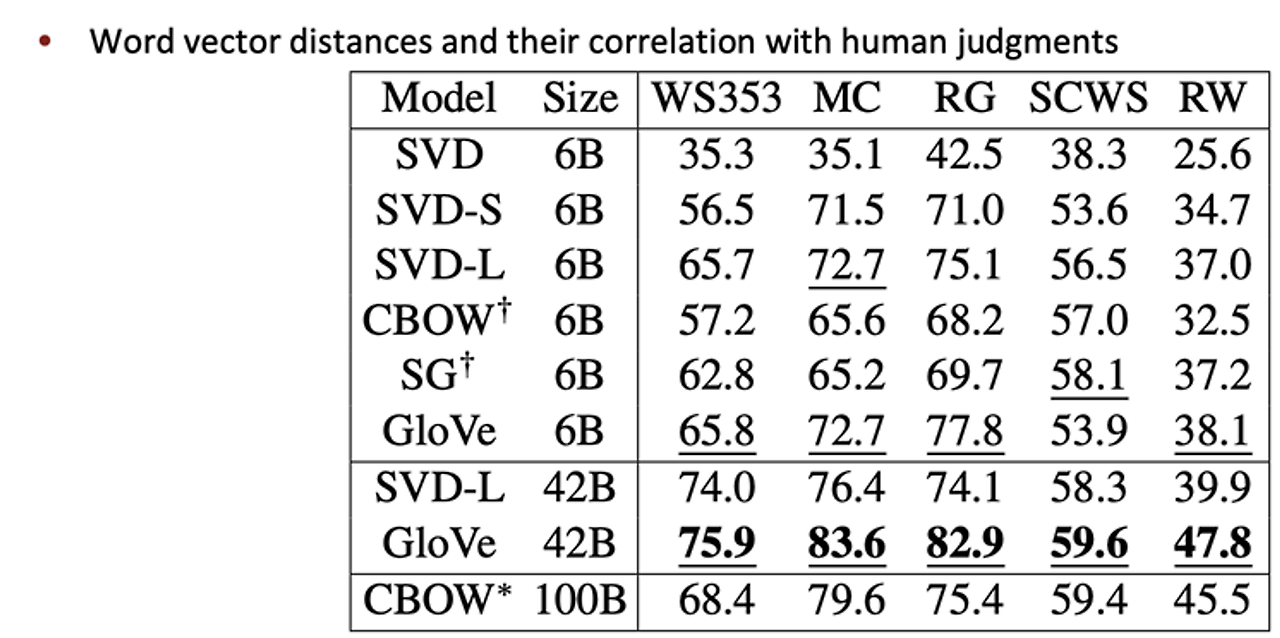
- 서로 다른 모델들이 유사성에 대해 얼마나 잘하는지에 대해 점수를 줄 수 있음
- comparatively better similarties
- svd – 나쁘지도 좋지도 않다.
- svd-s svd-l이 훨씬 좋음
- word2vec이 더욱 좋음
Extrinsic word evaluation
- NER(Named Entity Recognition, NER 벡터 모델이 명명된 개체 인식)
- 사람, 조직, 위치 등의 개체를 식별함
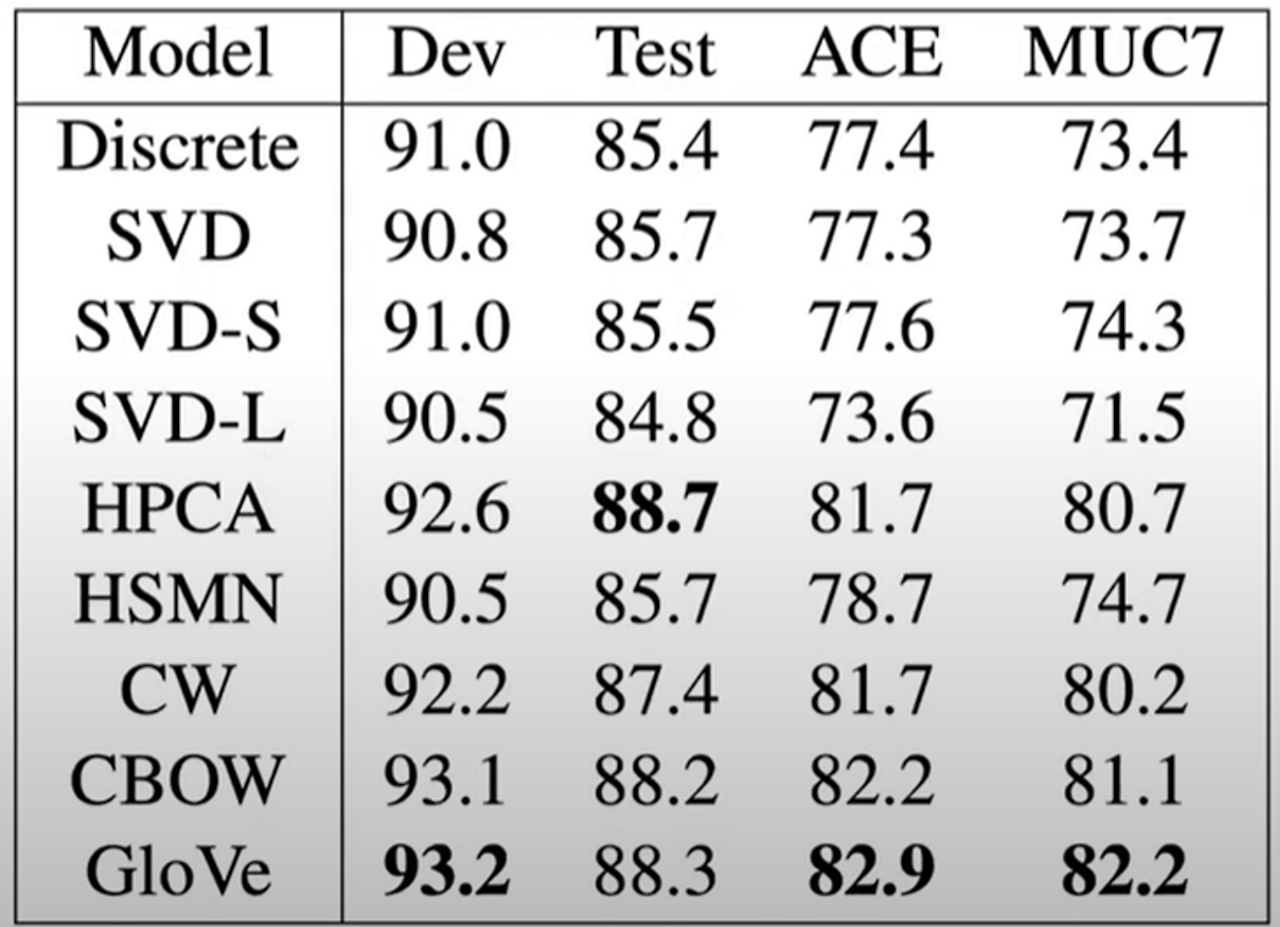
- GloVe 모델이 다른 모델들보다 더 우수한 성능을 보임
다의어를 해결하는 방법
PIKE (뜻이 10개), 눈과 같은 다의어
- 10개의 뜻으로 단어 벡터로 나누게 되면, 단어의 의미를 확실하게 나누는 것도 불완전하고 복잡
- "PIKE" 단어 벡터를 10개로 나누기보다, 모든 의미에 대한 알파값을 구하고 해당 의미 벡터와 알파값을 곱한 합을 벡터로 할 것
- EX) 사람의 눈 벡터, 내리는 눈 벡터

(1) 단어 주위의 window 클러스터링한다
(2) 유의어에 대해 서로 다른 클러스터들의 단어들로 훈련시킨다
단점
- 복잡함
각 의미마다 개별 벡터를 학습하는 것은 비효율적
EX) pike는 철도, 노선, 도로의 뜻이 있음. 그러나 이건 교통수단으로 통일할 수 있음.
=> 단어의 유형마다 하나의 단어 벡터를 갖게 하려면 어떻게 해야할까?
Linear Algerbraic Structure of Word senses, with applications to polysemy
선형 대수 구조와 다의성 적용
단어의 여러 의미가 Linear Superposition으로 표현될 수 있다.
- 선형 조합 수식

- α(가중치) 계산
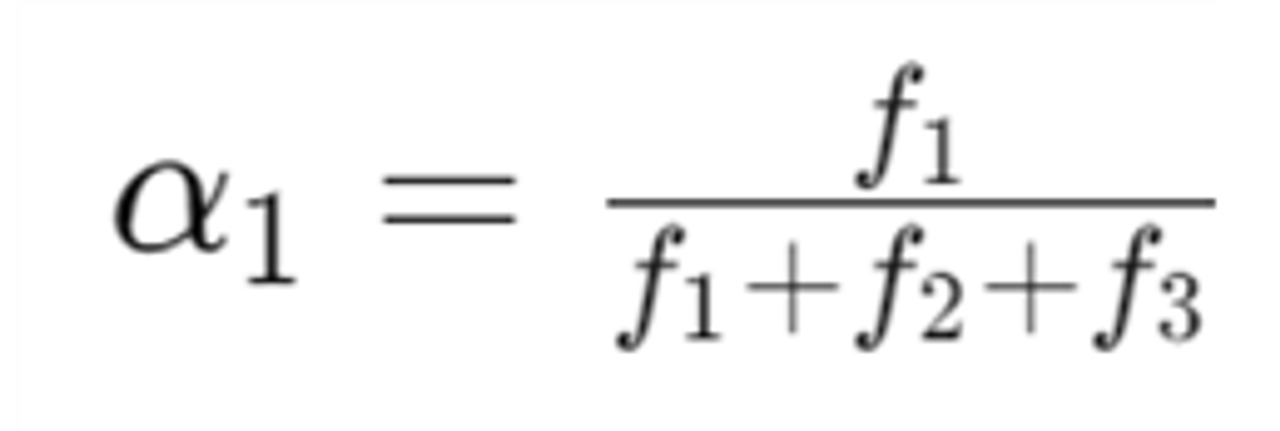
f: 각 의미의 빈도수
- 빈도만큼 벡터의 크기가 커지기 때문에 비례하여 해당 단어의 벡터 의미에도 반영하게 됨. sparse coding을 사용하여 단어의 의미를 분리할 수 있다
추가내용
sparse coding이란? 벡터 공간에서 각 단어의 의미를 별도의 벡터로 분리하는 기법 데이터를 희소 벡터로 표현,
대부분의 기저 벡터의 계수는 0 + 몇 개의 활성화된 기저 벡터(0이 아닌 값)
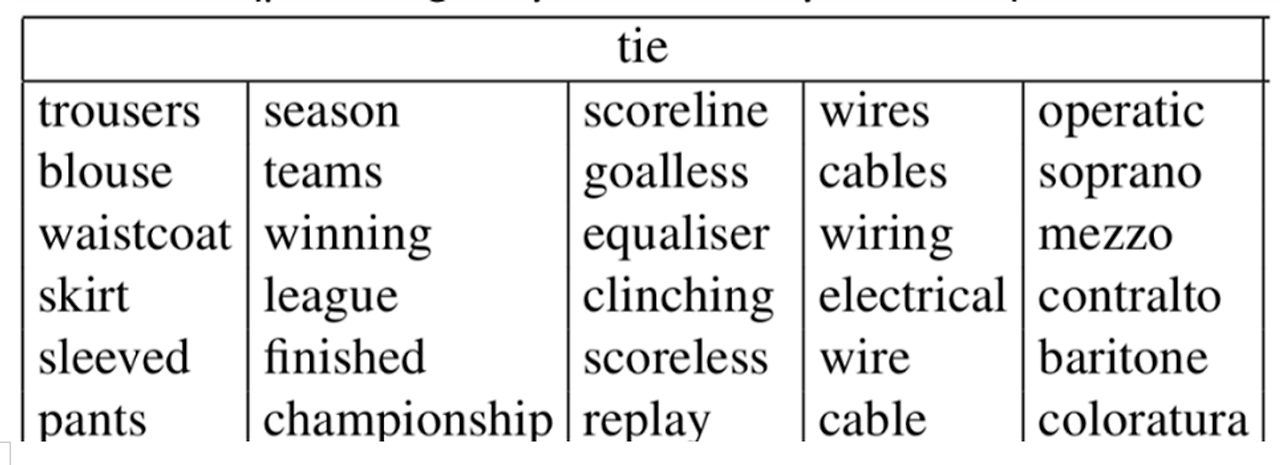
이처럼 종류별로 의류 스포츠 전기 음악으로 나뉘어짐